I interact with many Patient Advocates, Privacy Advocates, and individual Patients that are frustrated at the state of Privacy Consent today. I am too, but potentially in a different way.
Interoperable Consent Standards
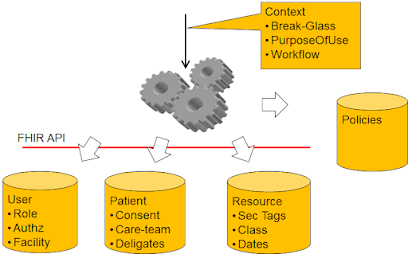
My main focus is on enabling Health Information to flow given proper Security and Privacy. Thus one of my focuses is on the interop standards that enable Privacy Consent to function properly. Enabling data to flow when it should, and blocking data from flowing when it should not. This involves simple consents like Allow or Deny. This involves a patient not yet having made a choice (default rules). This involves a patient changing their mind. This involves a patient explicitly authorizing a given kind of access by a given kind of user... etc
These Consent needs are very itemizable. I have been involved (sometimes lead) the efforts to define an Interoperable Standard for these use-cases in IHE for Document Sharing Exchanges (BPPC, APPC, XUA), and in CDA (CDA Consent), and in FHIR (FHIR Consent). The application of security vocabulary as request context (purposeOfUse), response obligations (do not re-disclose), and data tags (confidential and sensitive). The creation of a Consent Service using User Managed Access functionality of OAuth (HEART).
I have been engaged by some of the nationwide exchanges to customize these for their needs, which turn out to look much like the IHE solutions. They mostly look for a reasonable subset of full capability of these standards that minimally meet their needs. This minimal view is important as building a trust domain requires that you get everyone within that domain to all equally implement the same thing. Thus a minimal subset that hits the realistic need (not theory) is more likely to get implemented fully.
Reality is that Consent is Local
Most of these situations, the consent is a local thing. That is to say that a custodial organization obtains consent, manages consent, and enforces consent with no visibility to the exchange beyond the enforcement of releasing documents or not. Thus the majority of situations have no need for an “Interoperable” consent, as they need only achieve it functionally. Thus most trust-frameworks make it clear that data released is released for the given context (purposeOfUse) and then falls under the custodial rules of the recipient.
The dominant Consent failure is also Local
This is where the biggest failures around Privacy Consent happen. They are NOT offered, or too few choices are offered, or too many exceptions to the Patient desire are embedded. Thus the patient data flows in cases that the Patient does not want it to flow. The patient data does NOT flow when the patient does want it to flow. And the Patient often has no visibility into when it did flow, or when it was denied to flow (traceability). These failures are local functionality (policy). Fixing these failures will not be aided by more Interop standards on the topic. Fixing these failures is only driven by Patient demand, Government backing of that demand, and Businesses having an interest in satisfying the patient, and/or their government. In the absence of this interest, Businesses will do what optimizes the Business bottom line... which is data-blocking to keep Patients from leaving, data-analytics on the data for benefit of the Business, etc.
But Interoperable Consents are needed
I am not happy with this state of Consent fact. I am comfortable with it, but I see so much more that could be done beyond what is happening today. The vast majority of use-cases today are “Treatment” purpose of use… a very narrow and well defined domain with simple trust framework needs.
A demonstration of this Consent for Treatment has been done at HIMSS multiple times, and reality is… no one cared to watch it. I say no one, but we all realize that is just a statement of percentage of people that care vs total HIMSS population. Likely hundreds of people care, and 20% of them showed up. The audience is just so small that it is not worth the energy needed to setup the presentation. This is why I blog, and also why my blog gets so few visitors. The math is just not very big.
Non-heterogeneous PurposeOfUse networks
There is an emerging force in HealthIT approaching, the Payer community that also want and need access to the data. The very data that we have enabled in the exchanges so far. This would be a "Payment" purpose of use. But this does not really stress the minimal implementation much at all, as the PurposeOfUse mechanism is something that was kept in the minimal set. And consent is still local when it comes to billing requests. Most healthcare, especially in the USA, get a consent that is effectively on Treatment, Payment, and normal hospital operations (maintenance).
There are some Government use-cases for population health that have used the exchanges. These are beyond Treatment, Payment, and Normal hospital operations. But are also a specific defined purpose of use.
The more important force is that the Patient wants to interact with these nationwide exchanges. This means a PurposeOfUse of "Patient. The Patient might choose to request their data move in ways not yet defined.
If we had a more comprehensive consent system, might that enable data to flow more freely and more broadly than today? Yes, but... Most of these consent rules could still be local. What is important for non-heterogeneous networks is a method of identifying the purpose(s) for which the data are requested, and for which the data are released. This is baked into the standards, but everyone must use these consistently and accurately.
Just in time Consent
The most interesting Interoperable Consent that I have come across is the Just-in-time Consent, other wise known as "Point of Care Consent". This is a setting where the patient has not pre-arranged a Consent, thus initial requests for data are denied. But one where the two (requesting and responding) have a trust-framework such that the responding organization trusts the requesting organization to get a Consent from the Patient, provide proof of that consent, and then the responding organization will release the data for the consented purpose. This Consent is mostly for Treatment, I have not seen it for other. This Consent tends to be a blanket PERMIT, no quilting of exceptions or stipulations. Thus this consent tends to be a simple binary "Interoperability" need. But it could be more complex. It could include the same features as any Consent. And THAT is when the Consent needs to be more than a binary, when it needs to have these conditions, clauses, expiration, etc all in a structured and coded form.
This is baked into the IHE-XUA (SAML), and IHE-IUA (OAuth) profiles. What is needed is a policy based trust-framework, a policy based vocabulary. and traceability for the evidence and terms of the consent. Care Quality has set these up. The vocabulary and evidence could use simple (BPPC), or comprehensive (APPC), or FHIR Consents.
And Interoperable Consents will happen
The standards organizations (IHE, HL7, ISO, etc) have done as much as they can at this point. They are not done, but the next steps for these standards organizations is not in the core standards space. The problem is in implementation guides and market demand.
Here is my best-case plan… I want to see the SAMHSA defined "Consent to Share" Implementation Guide, come back to HL7 to be balloted, published, and maintained. I see this happening next year. I do NOT see this being driven by security workgroup or CBCP. I see this being driven by Patient Empowerment workgroup with security and CBCP as interested parties (not co-sponsors). I think this has the best chance to succeed.
Do I think that security couldn’t make it happen? No. But if security (or CBCP) did the project, no one outside of our workgroups would care. A specification that is ignored is not useful.
Why next year, and not now? Because Patient Empowerment workgroup is deep in two other projects at this time. Both of which have a high interest and strong engagement. PLUS these have gotten the attention of Argonaut, and thus the EHR vendors. I want to see these succeed (so don’t overload them with yet another project). And once they succeed, consent will take off with the momentum.
Conclusion
The most important point is that consent is mostly a local thing, that results in data being withheld to an external request or allowed. There are very few use-cases where a consent must be anything more than that. Fewer than that where that consent must be in an interoperable format. And fewer than that where there is a trust-framework to make an interoperable consent work. And fewer where the recipient has different custodial rules than the original custodian. Yes we design things like Consent Resource and Consent Service to these needs. But we must recognize that they are not actually compelling.
See my other articles on Consent