Privacy Consent can be viewed as a "State Diagram", that is by showing what the current state of a patients consent, we can show the changes in state. This is the modeling tool I will use here.
I will focus on how Privacy Consent relates to the access to Health Information, that is shared through some form of Health Information Exchange (HIE). The architecture of this HIE doesn't matter, it could be PUSH or PULL or anything else. The concepts I show can apply anywhere, but for simplicity think only about the broad use of healthcare information sharing across organizations.
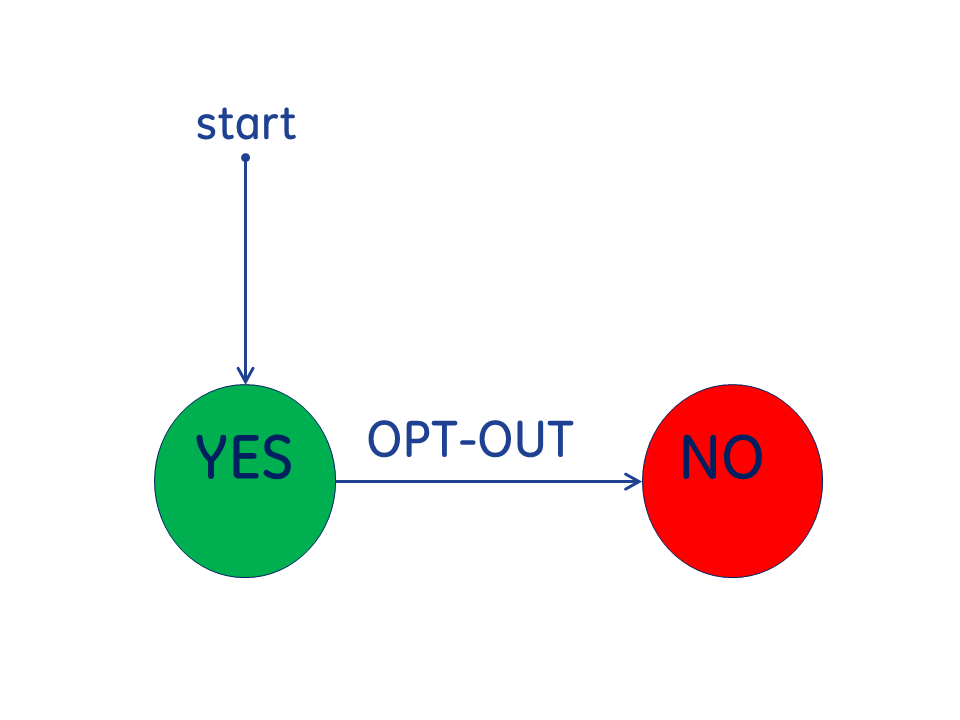
There are two primary models for Privacy Consent, referred to as "OPT-IN" and "OPT-OUT".
Privacy Consent of OPT-IN
This model is also referred to as "Implicit Consent". The USA HIPAA Privacy Regulation is utalizes this model for Privacy Consent within an organization. It is not clear to me that this HIPAA Privacy Regulation 'Implicit Consent' is expected to be used outside the original Covered Entity. It is a model used by many states in the USA.
The advantages typically pointed to with this model is that many individuals don't want to be bothered with the choice, these individuals trust their healthcare providers. Another factor often brought up is that when health treatment is needed, the patient is often not in good health therefore not well capable of making decisions; this however focuses on legitimate uses and ignores improper uses. Privacy worries about both proper and improper access.
Privacy Consent of OPT-IN
 At the right is the diagram for an OPT-IN environment. In an OPT-IN environment the patient is is given the opportunity to ALLOW sharing of their information. This means that there is a presumption that the patient does not want their health information shared. I would view it more as a respect for the patient to make the decision.
At the right is the diagram for an OPT-IN environment. In an OPT-IN environment the patient is is given the opportunity to ALLOW sharing of their information. This means that there is a presumption that the patient does not want their health information shared. I would view it more as a respect for the patient to make the decision.This model is used in many regions, even within the USA. With an HIE this model will work for many use-cases quite nicely. Contrasted with the HIPAA Privacy use of Implicit Consent, which is likely a better model for within an organization. The two models are not in conflict, one could use Implicit Consent within an organization, and OPT-IN (Explicit Consent) within the HIE.
Privacy Consent Policy

The important thing is that there are different rules. The state of "YES" doesn't mean that no rules apply, there are usually very tight restrictions. The state of "NO" often doesn't truly mean no use at all. There is usually some required government reporting, such as for the purposes of protecting public health.
Privacy Consent: YES vs NO

Thus what seems like a very simple state diagram for OPT-IN or OPT-OUT; one must recognize that they need to support transition between "YES" and "NO".
Privacy Consent of Maybe

Note that the state diagram shows transitions between all three states. It is possible that one goes into the "MAYBE" state forever, or just a while.
Privacy Consent is a Simple State Diagram
I hope that I showed that Privacy Consent is simply state transitions. I really hope that I explained that each state has rules to be applied when a patient is in that state. Implicit (OPT-OUT) and Explicit (OPT-IN) are simply an indicator of which state does one start in, which state is presumed when there is an absence of a patient specific decision. The rules within each state are the hard part. The state diagram is simple.Other Resources
Patient Privacy controls (aka Consent, Authorization, Data Segmentation)
- Defining Privacy
- Universal Health ID -- Enable Privacy
- Texas HIE Consent Management System Design
- Simple and Effective HIE Consent
- Advanced Access Controls to support sensitive health topics – a simple solution to sensitive health.
- IHE - Privacy and Security Profiles - Basic Patient Privacy Consents
Access Control (Consent enforcement)
- Advanced Access Controls to support sensitive health topics
- Policy Enforcing XDS Registry
- Healthcare Metadata
- IHE - Privacy and Security Profiles - Access Control
- Data Classification - a key vector enabling rich Security and Privacy controls
- Healthcare Access Controls standards landscape
- Handling the obligation to prohibit Re-disclosure
- Access Controls: Policies --> Attributes --> Implementation

