The IHE IT-Infrastructure committee has approved four milestones; sIPS, NPFS, DSUBm, and PDQm match alternative. This winter quarter will be a lighter load, recognizing the holidays: Patient Scheduling, prospective look at FHIR R5/6, and evaluating impact of Gender Harmony.
This article is published before these are formally published, so I include a (will be at) link that likely won't be proper until later in November.
(updated to clarify the links and add YouTube presentation links)
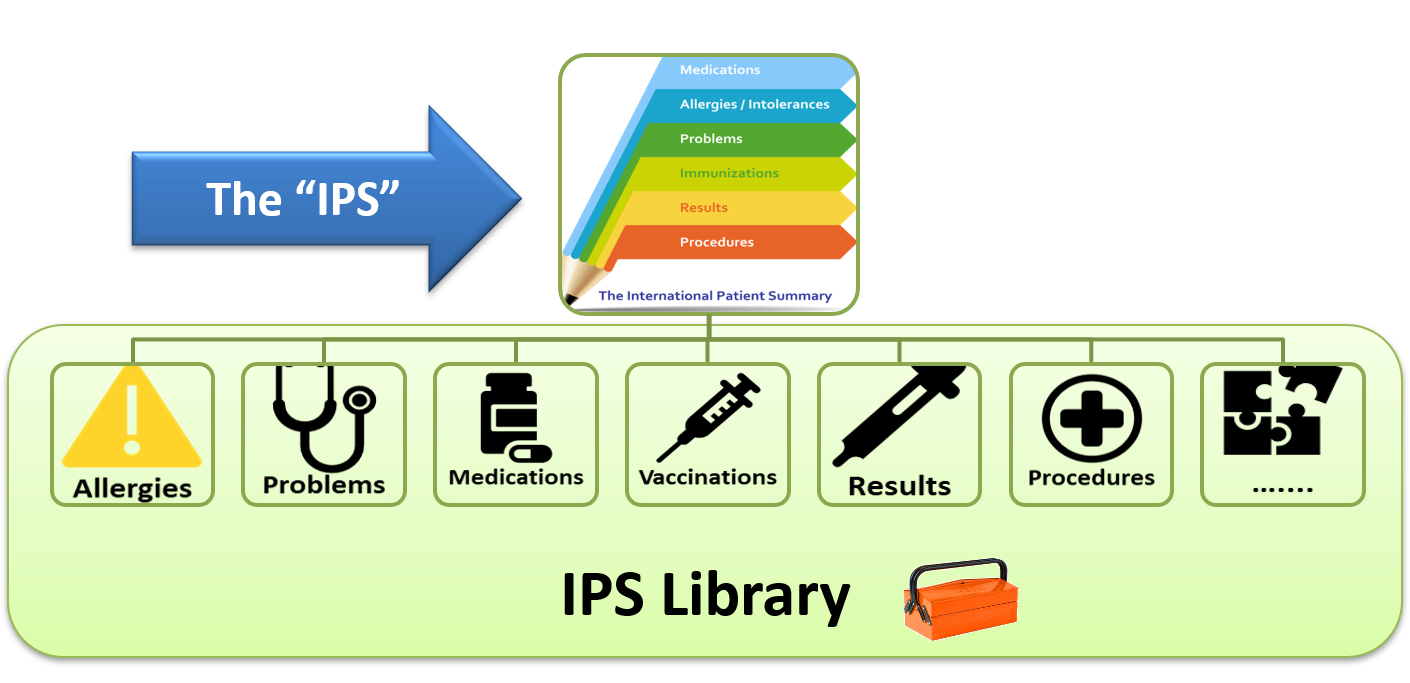
Sharing IPS (sIPS)
Formal Publication -- https://profiles.ihe.net/ITI/sIPS
This Implementation Guide was out for Public-Comment and is now ready for Trial-Implementation.
The Sharing of IPS (sIPS) IHE Profile provides for methods of exchanging the HL7 International Patient Summary (IPS), using IHE Document Sharing Health Information Exchange but does not modify the HL7 IPS specification.

as defined in the ISO 27269 data model specification, utilizes IHE’s document sharing infrastructure including cross-community, HIE, direct exchange models, and more. It has been designed specifically to remove barriers to adoption, by leveraging architectures that are currently implemented, well-established, and robust.
The sIPS Profile provides implementation guidance to vendors and implementers and joins a growing suite of IPS standards artefacts contributed by a variety of Standards Development Organizations (SDOs) and coordinated by the Joint Initiative Council for Global Health Informatics Standardization (JIC).

Non-Patient File Sharing (NPFS)
Formal Publication -- https://profiles.ihe.net/ITI/NPFS
This Implementation Guide was converted from PDF form into the Implementation Guide form and is now transitioning to Trial-Implementation again.
The Non-Patient File Sharing (NPFS) Profile defines how to share non-patient files such as clinical workflow definitions, domain policies, and stylesheets. Those files can be created and consumed by many different systems involved in a wide variety of data sharing workflows.
YouTube presentation.
Document Subscription for Mobile (DSUBm)
Public-Comment -- https://profiles.ihe.net/ITI/DSUBm/1.0.0-comment
This Implementation Guide is going to Public-Comment as a new specification that provides for subscriptions and notification mechanisms to Document Sharing publications.
This profile can be applied in a RESTful-only environment as MHDS but it can also be used with different non-mobile profiles as XDS.b and DSUB. This profile intends to grant the same functionality as the DSUB profile and its supplements regarding Document subscription but also adding some other functionalities (e.g. Subscription Search).

YouTube presentation.
Patient Demographics for Mobile (PDQm)
Public-Comment -- https://profiles.ihe.net/ITI/PDQm/3.0.0-comment
This Implementation Guide is going to Public-Comment with a new alternative for looking up a Patient using the FHIR $match operation.

YouTube presentation.
Winter Quarter
The winter quarter we will continue working on:
- Scheduling -- a vendor agnostic specification providing FHIR APIs and guidance for access to and booking of appointments for patients by both patient and practitioner end users, including cross-organizational workflows. This specification is based on FHIR Version 4.0.1, and references the Schedule, Slot, and Appointment resources. This workflow profile defines transactions that allow a scheduling client to obtain information about possible appointment opportunities based on specific parameters, and, based on that information, allow the client to book an appointment.
- Evaluating FHIR R5 to improve FHIR core for R6 -- The workgroup will look at what it might take to convert the current set of FHIR R4 implementation guides to R5, with the goal to uncover concerns with FHIR core that IHE should recommend be remediated in FHIR core R6. There is no intention by IHE to publish these FHIR R5 implementation guides as market demand is very low.
- Evaluating the impact of Gender Harmony on IHE Profiles -- HL7 has published a set of implementation guides covering the Gender Harmony use-cases including HL7 v2, CDA, and FHIR. The workgroup will be evaluating the potential to update existing IHE Profiles to add these capabilities.