Lately there has been more groups thinking about how Patient contributions to the medical record might be distinguished from clinician authored data. Also, how AI contributions could be recognized as distinct. This article will cover a couple of methods that exist in FHIR core, but also exist in CDA and HL7 v2. I will only speak about FHIR.
General need
The general need is to express the provenance of a Resource or an element within a Resource. For this we have two different solutions that are related, but distinct. Two solutions as sometimes one needs a lightweight solution, sometimes you need full powerful Provenance.
As stated above sometimes you want to indicate the whole resource was authored by the Patient, sometimes you just want to indicate one or more elements within the resource was authored by the Patient.
E.g.
- Patient record of body weights taken at home
- Patient's partner indicated the Patients nickname
- AI produced a CarePlan based on current labs and observations; relative to clinical care guidelines, and care plan definitions.
- AI produced an Observation interpretation code value
Using Tags
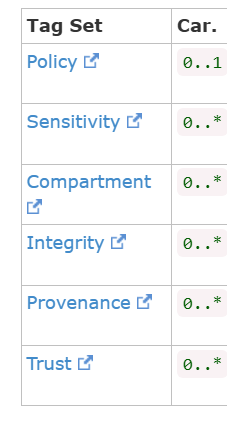
All of the FHIR Resource have a
meta.security coding element that has a valueSet binding that includes a set of provenance codes that include a set of codes for this usecase. The fact that these are indicated as .security tags does not mean they are exclusively only to be used for security purposes; and note that security is the domain of managing risks to (Confidentiality, Availability, and Integrity). Provenance comes under Integrity and a bit of Availability.
There are some that will see the
.meta.tag. The temptation is strong (especially with those in the AI space); but this is not the right element. This is not wrong to use this element, but putting your code here will mean that those looking in meta.security will not find what they are looking for. So we should agree to use the meta.security and the given standardized codes (when they apply).
The ValueSet available for meta.security covers all of the security space including Availability and Integrity. Most important here are the Provenance sub valueSet, but you should also note that the Integrity valueSet has some very useful codes (highly reliable, reliable, uncertain, unreliable)
- clinician
- device
- healthcare professional
- patient acquaintance
- patient
- payer
- professional
- substitute decision maker
- artificial intelligence
- dictation (software)
I am not all that clear on what the distinction between reporting vs asserting is; nor do I understand the distinction between a clinician and a healthcare professional. I think these distinctions exist in the core codeSystem so that they can be further profiled and made distinct.
So, use these codes at the Resource.meta.security to indicate that the whole resource is contributed by one of those codes. Here is an example of how a whole Observation would be indicated as contributed by AI.
Using Tags at the element level
Where the FHIR Resource .meta.security with the code of patient would be understood as indicating that the whole of the resource was asserted to by the patient; often this is too blunt of a tag. Sometimes one just wants to indicate an element was contributed to differently. Like the example above where the patient acquaintance indicate their nickname. Thus one wants to tag that only that nickname was contributed by the patient acquaintance. For this we use the extension that is defined in the
Data Segmentation for Privacy (DS4P), again pointing out that this IG is broader than just data segmentation and/or privacy.
So, here we show an example of a Patient resource where the nickname was contributed by the patient acquaintance. In this case we need to have the
inline code at the Resource.meta.security level to indicate that inline codes are used in this Resource, as inline codes can appear on any element, thus it is expensive to look for inline codes.
{
"use": "nickname",
"given": [
"Jimmy"
],
"extension": [
{
"url": "http://hl7.org/fhir/uv/security-label-ds4p/StructureDefinition/extension-inline-sec-label",
"valueCoding": {
"code": "PACQAST",
"system": "http://terminology.hl7.org/CodeSystem/v3-ObservationValue",
"display": "patient acquaintance asserted"
}
}
]
}
Provenance Solution
The tagging solution, even with the element level capability, often can't convey enough information. Like who is this patient acquaintance, when was that element added, why was it added, who was involved in agreeing to add that to the record, where did that data come from, how was the original data used, etc... All those things that are part of Provenance ( Who, What, Where, When, and Why). Now recording all of this will make the database rather full of Provenance data, where as the tag mechanism is very focused and carried fully by the data. But sometimes one does need to know more provenance detail.
In the Provenance, these same codes from above can be used for the various Agent(s), but there are more nuance available in the participation type codeSystem. So a Provenance that indicates that the whole Observation was contributed by the Patient would look like this.
{
"resourceType" : "Provenance",
"id" : "example1",
"target" : [{
"reference" : "Observation/obs2/_history/1"
}],
"recorded" : "2021-12-07T12:23:45+11:00",
"agent" : [{
"type" : {
"coding" : [{
"system" : "http://terminology.hl7.org/CodeSystem/v3-ParticipationType",
"code" : "INF"
}]
},
"who" : {
"reference" : "Patient/pat3"
}
}]
}
Provenance at the element level
Where as the Patient nickname example would look like (Note the use of the `targetElement` extension). There is also a `targetPath` extension where a path can be used.
{
"resourceType" : "Provenance",
"id" : "example2",
"target" : [{
"extension" : [{
"url" : "http://hl7.org/fhir/StructureDefinition/targetElement",
"valueUri" : "n2"
}],
"reference" : "Patient/pat3/_history/1"
}],
"recorded" : "2021-12-08T16:54:24+11:00",
"agent" : [{
"type" : {
"coding" : [{
"system" : "http://terminology.hl7.org/CodeSystem/v3-ParticipationType",
"code" : "INF"
}]
},
"who" : {
"reference" : "RelatedPerson/f001"
}
}]
}You can, in
Provenance.target, use the extension targetElement or targetPath to indicate that just some of the data within a Resource was patient contributed. See examples 1, 2, and 3 -- in Provenance examples -
https://build.fhir.org/provenance-examples.htmlConclusion
The .meta.security and Provenance are not exclusively to be set or used by Security. These values might be populated by a Security Labeling Service (SLS), but that service should not overwrite values that have been explicitly set. Yes, they are used by Security, but security also uses many other elements in the resources that many think are only useful for clinical use.