I already have one proposal for the transition from the current Federated Health Information Exchange to supporting FHIR, that is based on a transition from CDA to FHIR-Documents. In that proposal, I make it clear that this is NOT an end-state, but rather a method to more smoothly transition. A key point of a smooth transition is that it does not stop what is working today, but provides methods of supporting the future for those early adopters. That proposal recognizes that today the communication pathway is XDS/XCA, and that communications pathway is content agnostic, meaning it can carry a FHIR-Document just as well as a CDA, PDF, JPEG, or TEXT document.
Note that just because the content being published is a "Document" does not mean that it must be consumed as a document. There are solutions such as the one from IHE (Mobile Cross-Enterprise Data Element Extraction - mXDE) that shows how to decompose documents into FHIR Resources, and provides for proper Provenance back to the source Documents.
Federated FHIR Resource Servers
In this article I am going to add another step to the smooth transition. In this article I am going to show how we can leverage much of the infrastructure that has been put into nationwide federation of health information exchanges, while enabling communication that is natively FHIR Query/Retrieve. In this proposal the data holder never creates a "Document", they provide a FHIR Server endpoint that can be queried. This idea of having a FHIR Server endpoint is not new, it is the fundamental first step of any data holder.

Note that "just use normal FHIR Query" is skipping the Security and Privacy aspects... I will get to those later. I mostly think that this is already addressed by the various security and privacy projects; they just haven't seen enough use to figure out where federation fits.
Federated Patient Record Location
We already have a functioning Patient Record Location standard that is being used with XCA to find the patient identities and locations where data are. The standard is XCPD. This standard is mostly used between the various communities, so is not something that a client app needs to care about. Yes, it is based on HL7 v3, and uses SOAP. I recognize that this is a drawback. My point is more that this is functional today, and it gives us what we need. Further the HL7 v3 and SOAP standard better supports the scale of federation that we need, something that http REST does not.
So, if we accept that XCPD can continue to be used to discover patient identities and locations where data are, then how do we determine the FHIR Server address? This is an important question as XCPD provides a "homeCommunityID" as the location, and that is an OID.
Converting homeCommunityID into a FHIR Server address
Fortunately, we already have the solution to this problem.
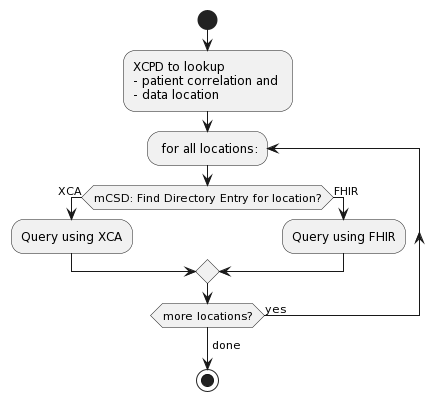
Today, with XCA, the homeCommunityID needs to be converted into the address of the XCA endpoint, and this done with a centrally managed Directory. This centrally managed Directory is already managed for the purposes of supporting XCA, so it is already in place. This centrally managed Directory is already founded on FHIR. Mostly the FHIR Resources: Organization, OrganizationAffiliation, Location, and Endpoint.
It is the Endpoint resource that we need to further refine. Whereas it is understood how to define an XCA endpoint; we just need to have a flavor of Endpoint profiled to show a FHIR Server endpoint. Once we have that, then the normal FHIR Server processing progresses. Looking at the FHIR Server metadata endpoint, and oAuth well-known details.
There is a very important Whitepaper by IHE on "Document Sharing Across Network Topologies", that like this article clarifies is more than just Document Sharing, but also FHIR Server endpoint. Video introduction.
Intermediate or Direct
Now for the smooth transition:
- A data holder can express that they both have XCA and FHIR endpoints. They don't need to choose which one they support.
- Value-Add intermediaries can be expressed in this Directory as the endpoint for a given set of Organizations.
- Value-Add intermediaries can also implement mXDE to provide the FHIR Server support on behalf of Organizations that are not yet ready to transition.
- Those that want data simply use the Federation discovery methods to find the patient identities and locations for a given patient, then lookup in the directory the alternatives for how to get data from that location and choose the best solution for them.
Like with the previous proposal to transition from CDA to IPS; the transition here is driven more by those that want to consume data, supported by the infrastructure and the data holders.
Thanks to Joe Lamy (AEGIS) for dialog resulting in this article.