I am reminded of "This too shall pass.", and I really hope it is true. The past two years have been monotonous, with very little positive things to get excited about. That said, I expect 2022 will simply be a workhorse of a year with small advancements that are not clear today. Yeah, that is the most blah prediction.
The most positive is that my household family continue to be COVID-19 free. However I lost my father with COVID-19 as a factor. COVID-19 has been the healthcare story in the standards I work on, but is also the thing that is preventing the standards groups from gathering and being more productive. I don't mind the pace slowdown, and initially didn't mind the lack of face-to-face meetings, but lately I have found myself wishing for the face-to-face workgroup meetings. I likely just want some of the positive meeting dynamics, while noting that most of the time the meetings were compulsory and a waste of time.
The last time I did a year-end report was at the end of 2017 - HIE Future is Bright - stepping into 2018. Looking back at that report, it is rather disappointing that none of the expectations have been achieved, yet so much has happened toward the direction of each of these. The activities that have happened are clear now that they were necessary, but of course at the time it felt like everything was ready for progress."The secret of getting ahead is getting started. The secret of getting started is breaking your complex overwhelming tasks into small manageable tasks, and then starting on the first one." - Mark Twain
- IHE whitepaper on Health Information Exchange models (3.7k)
- From Implementation-Guide to IHE-Connectathon (2.7k)
- Healthcare use of Identity level of assurance (2k)
- When is a document not a Document but still a document? (1.6k)
- Agile improvements toward #FHIR (1.5k)
- Security of #FHIR implementations concerns (1k)
2021 Themes
Health Information Exchange using FHIR
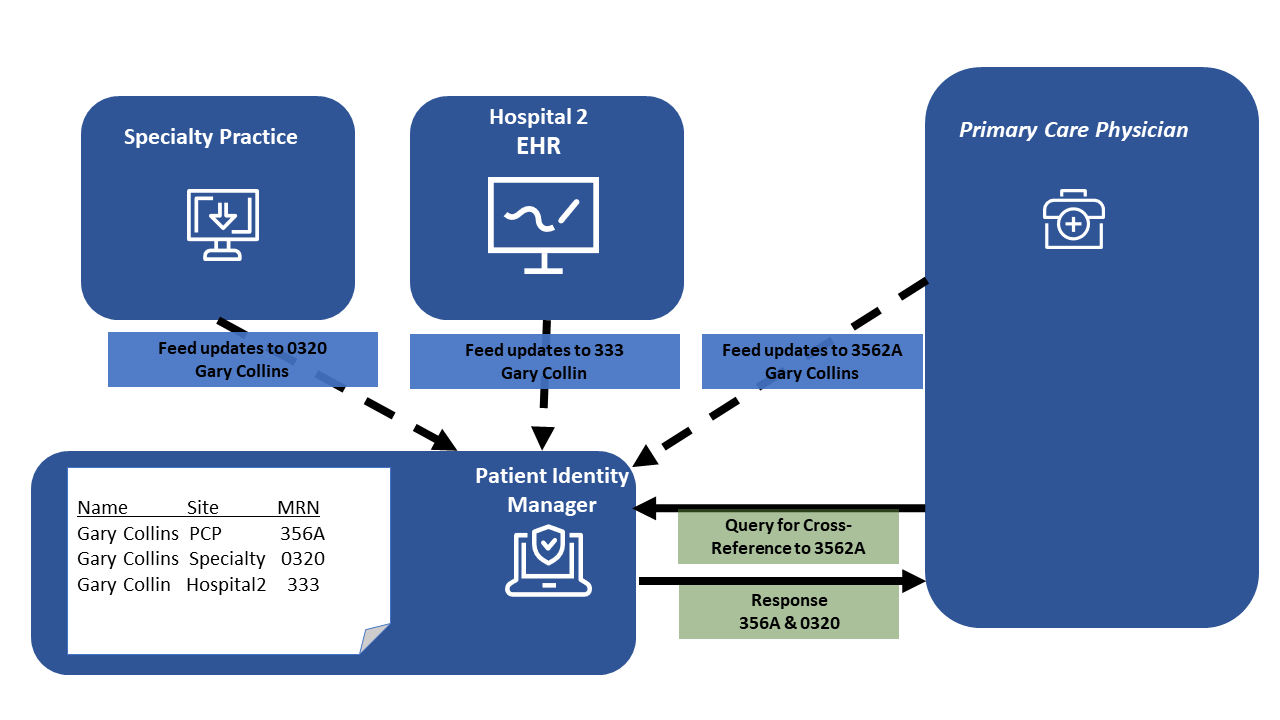
- IHE conflicting Patient Identity Feed patterns
- Updates to IHE foundational #FHIR profiles MHD, PDQm, and PIXm
- IHE IT-Infrastructure fall 2021
- #FHIR Basic AuditEvent for generic RESTful actions
- FHIR Document Digital Signatures
- FHIR data in existing Nationwide Health Information Exchange
- Book: IHE Profiles for Health Information Exchange
- User Management on FHIR
- Healthcare use of Identity level of assurance
- IHE is on #FHIR
- Why use current Exchange infrastructure rather than starting over?
- Set of documents that are very focused #FHIR
- When is a document not a Document but still a document?
- Agile improvements toward #FHIR
- IHE ITI February 2021
- IHE whitepaper on Health Information Exchange models
- From Implementation-Guide to IHE-Connectathon
- Actual Consent is more important than more standards for Consent
Healthcare IT Security
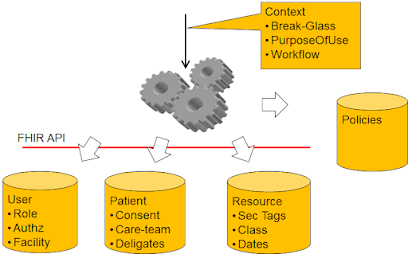
- Mantras for Secure FHIR Development
- Please secure your #FHIR API and Apps
- Security of #FHIR implementations concerns
- #FHIR Basic AuditEvent for generic RESTful actions
- FHIR Document Digital Signatures
- InScope podcast: #FHIR security
- Healthcare use of Identity level of assurance
Presenting and giving Tutorials
- Mantras for Secure FHIR Development
- HIMSS presentation on FHIR CarePlan
- InScope podcast: #FHIR security
- Tutorial Links
- FHIR Security & Privacy Tutorial