Most discussions about FHIR are simple interaction diagrams like this:
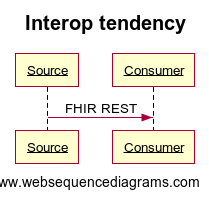
The Real story needs to consider that the "Source" above is a single box representing 10,000 potential source systems that hold data about the patient: (map is a static view of CareQuality network)
 More important is that the above map only represents Clinical sources. There are also Payer sources, and many more...
More important is that the above map only represents Clinical sources. There are also Payer sources, and many more...
So there is a real scale problem with the above.
If we look at the use-case of Treatment needing to get a current view of data. We could imagine that EACH of these Sources will publish a FHIR endpoint and publish US-Core based Common Clinical Data Set (CCDS). Thus your Source system will need to query them all.
The diagram is not all that more complex as in a sequence diagram we just add a loop. But we all need to understand that loop is multiplied by all sites that indicate the patent has data
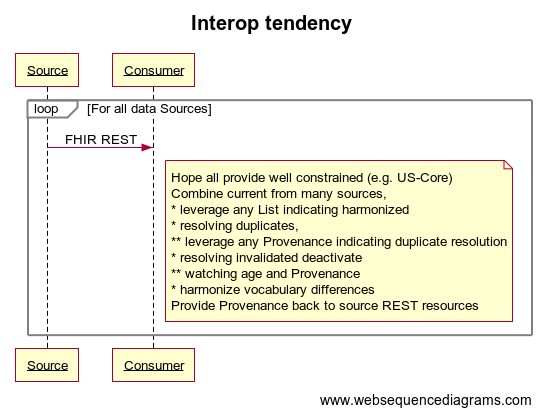
You will note that EACH Consumer system needs to do some detailed combination of the results.
So one might need to combine REST access with Document content. One could optimize to NOT pull documents from sites that provided REST access to current data.
I show this being implemented by an Intermediary. I am not proposing a common Intermediary, although that is possible. I suspect that these Intermediary will have organizational customization. That is that the Consumer organization will want to control the algorithm and output. Thus the Intermediary is likely as many as there are Consuming organizations. This might be able to be generalized for a region. But the more one moves it to a central position, the more one creates potential Privacy concerns.
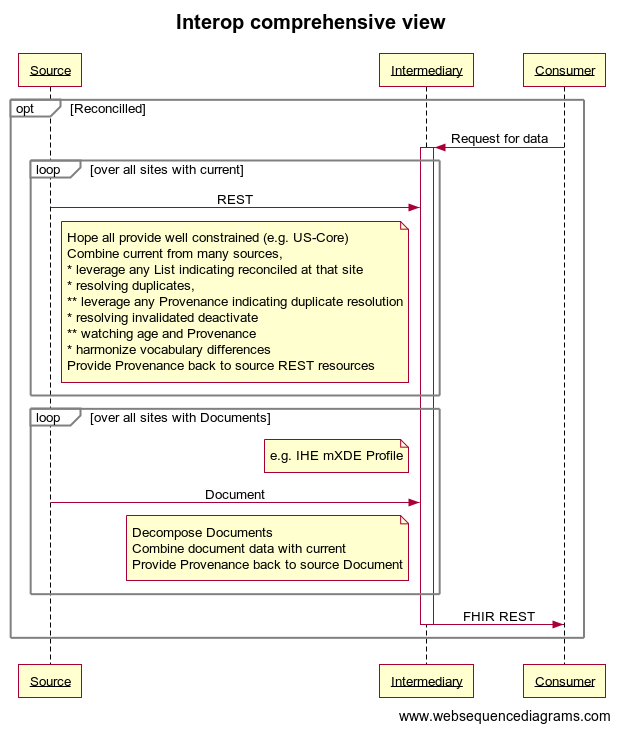
I did not address how the sub-set of sites that have data on this patient are discoverd. There likely needs to be some level of Federated search, or centralized Record Locator, or a combination of both.
I did not address how security is addressed. There could be a national managed security infrastructure, but that is another kind of scale problem. It is possible, but not addressed in this article.
I did not address how Privacy is addressed. I expect that this will continue to be a Source side management. That is that each Source manages their responsibility to protect the data and to release it as appropriate according to the Consent they have on file. There likely is a need for "Point-of-Care Consent".
Likely many more too
----------------------------------- websequence diagram source ---------------------------
title Interop tendency
participant Source
participant Intermediary
participant Consumer
note left of Source: Broad tendency
loop Current Details
note right of Source: Many sources for each site patient Visited
Source->Consumer: FHIR REST
note right of Source
Note that results can include
DocumentReference to documents flow
end note
end
loop Discharge or Episode or Problem or CarePlan or Notes
note right of Source
Targeted to one document sources or all
Clinical Documents cover 5 Principles
* Persistence
* Wholeness
* Stewardship
* Context
* Potential for authentication
Documents could be CDA or FHIR documents
Not optimial but may be TEXT or PDF
Transport can be XD* or MHD (FHIR DocumentReference)
end note
Source->Consumer: FHIR/CDA Document
end
loop Population on a cohort
note right of Source: Many sources
Source->Consumer: FHIR Bulk access
end
note left of Source
Comprehensive view
using Intermediary
end note
opt Reconcilled
Consumer->+Intermediary: Request for data
loop over all sites with current
Source->Intermediary: REST
note left of Intermediary
Hope all provide well constrained (e.g. US-Core)
Combine current from many sources,
* leverage any List indicating harmonized
* resolving duplicates,
** leverage any Provenance indicating duplicate resolution
* resolving invalidated deactivate
** watching age and Provenance
* harmonize vocabulary differences
Provide Provenance back to source REST resources
end note
end
loop over all sites with Documents
note left of Intermediary: e.g. IHE mXDE Profile
Source->Intermediary: Document
note left of Intermediary
Decompose Documents
Combine document data with current
Provide Provenance back to source Document
end note
end
Intermediary->-Consumer: FHIR REST
end
Many Sources (n != 1)
The Real story needs to consider that the "Source" above is a single box representing 10,000 potential source systems that hold data about the patient: (map is a static view of CareQuality network)

So there is a real scale problem with the above.
If we look at the use-case of Treatment needing to get a current view of data. We could imagine that EACH of these Sources will publish a FHIR endpoint and publish US-Core based Common Clinical Data Set (CCDS). Thus your Source system will need to query them all.
The diagram is not all that more complex as in a sequence diagram we just add a loop. But we all need to understand that loop is multiplied by all sites that indicate the patent has data
Combining Many Sources
You will note that EACH Consumer system needs to do some detailed combination of the results.
- Hope all provide well constrained (e.g. US-Core)
- need to be robust to variations
- Combine current data from many sources,
- leverage any List indicating reconciled at that site
- hope republished data preserved original id
- resolving duplicates
- leverage any Provenance indicating duplicate resolution
- resolving invalidated deactivate
- watching age and Provenance
- harmonize vocabulary differences
- Provide Provenance back to source REST resources
Not everyone will publish US-Core level resources
Reality is that many of the sites won't provide US-Core level access, but will only provide Documents. Best-case is that it is a On-Demand Medical Summary, which does cover the same data and does provide only current data. But may be a set of discharge summary, or episode documents.So one might need to combine REST access with Document content. One could optimize to NOT pull documents from sites that provided REST access to current data.
I show this being implemented by an Intermediary. I am not proposing a common Intermediary, although that is possible. I suspect that these Intermediary will have organizational customization. That is that the Consumer organization will want to control the algorithm and output. Thus the Intermediary is likely as many as there are Consuming organizations. This might be able to be generalized for a region. But the more one moves it to a central position, the more one creates potential Privacy concerns.
NOT fully discussed here
I did not address how the sub-set of sites that have data on this patient are discoverd. There likely needs to be some level of Federated search, or centralized Record Locator, or a combination of both.
I did not address how security is addressed. There could be a national managed security infrastructure, but that is another kind of scale problem. It is possible, but not addressed in this article.
I did not address how Privacy is addressed. I expect that this will continue to be a Source side management. That is that each Source manages their responsibility to protect the data and to release it as appropriate according to the Consent they have on file. There likely is a need for "Point-of-Care Consent".
Likely many more too
----------------------------------- websequence diagram source ---------------------------
title Interop tendency
participant Source
participant Intermediary
participant Consumer
note left of Source: Broad tendency
loop Current Details
note right of Source: Many sources for each site patient Visited
Source->Consumer: FHIR REST
note right of Source
Note that results can include
DocumentReference to documents flow
end note
end
loop Discharge or Episode or Problem or CarePlan or Notes
note right of Source
Targeted to one document sources or all
Clinical Documents cover 5 Principles
* Persistence
* Wholeness
* Stewardship
* Context
* Potential for authentication
Documents could be CDA or FHIR documents
Not optimial but may be TEXT or PDF
Transport can be XD* or MHD (FHIR DocumentReference)
end note
Source->Consumer: FHIR/CDA Document
end
loop Population on a cohort
note right of Source: Many sources
Source->Consumer: FHIR Bulk access
end
note left of Source
Comprehensive view
using Intermediary
end note
opt Reconcilled
Consumer->+Intermediary: Request for data
loop over all sites with current
Source->Intermediary: REST
note left of Intermediary
Hope all provide well constrained (e.g. US-Core)
Combine current from many sources,
* leverage any List indicating harmonized
* resolving duplicates,
** leverage any Provenance indicating duplicate resolution
* resolving invalidated deactivate
** watching age and Provenance
* harmonize vocabulary differences
Provide Provenance back to source REST resources
end note
end
loop over all sites with Documents
note left of Intermediary: e.g. IHE mXDE Profile
Source->Intermediary: Document
note left of Intermediary
Decompose Documents
Combine document data with current
Provide Provenance back to source Document
end note
end
Intermediary->-Consumer: FHIR REST
end
Scale outside healthcare is proven for REST in use cases with many clients to one server (N-1). In health IT we need both to scale (N-M).
ReplyDelete