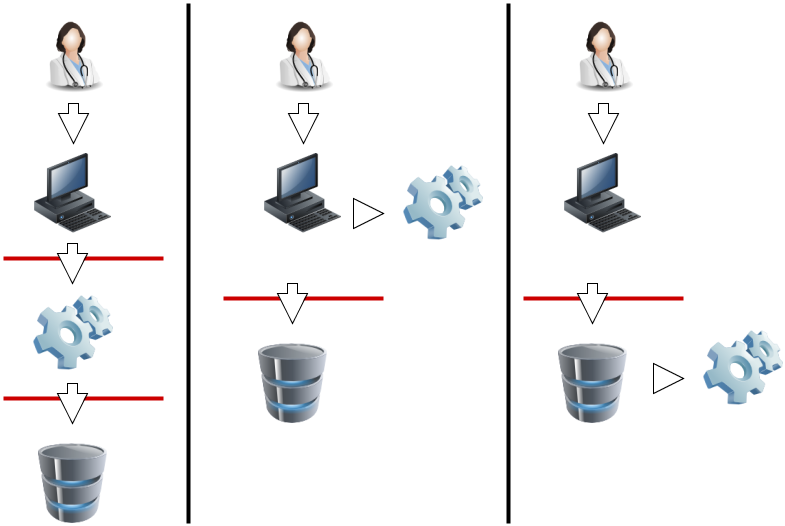
The concept of de-identification is a reoccurring theme in my circles. The use of the term de-identification that I use is the broader term well beyond the constraints of HIPAA. I use the term de-identification to refer to the process of reducing risk of privacy or identity exposure through modifying the data. This includes using pseudonyms, known as pseudonymization; and also includes removing data elements, known as anonymization. Therefore De-Identification is made up of both Pseudonymization and Anonymization.
I am involved in much of the standards work in this space, actively working in IHE on a handbook and ISO on updates to the core standard on the subject. In all of these cases we are trying to make the 'art' of de-identification more measurable, repeatable, and approachable. Too often it is seen as too hard, more often it is seen as simple and thus mistakes are made. The goal I have is to make it clear.
Why De-Identify?
First, one must understand that de-identification is just a method of lowering risk. The only way to get risk to zero is to have zero data. Even one data-element that one might consider to be purely clinical data does narrow down the population. Just to indicate that the weight of the subject is 203lbs will tell you much about the subject, if that value is 3lbs and you know the subject is a premature-baby, and if it is 403lbs it is clear you have limited the population. The first point is that all data are potentially identifiable, some data are less so.
Second, one must recognize that some data are outright Direct Identifiers. These data are in no uncertain terms identifiers. Full-Name is the most obvious. A Direct Identifier is something that is publicly known (knowable), therefore full-addresses, phone numbers, credit-card-numbers, and drivers-license-numbers. These items clearly can't be included in the de-identified data set. So they each need to be identified as a risk to be mitigated.

There are also a class of data that can be used in combination with other data in the data-set to identify a subject. Such as postal-codes, sex, date-of-birth, hospital identifier, or date-of-procedure. These are risky to be left in, so they need to be identified as potential to be mitigated.
The task of De-Identification is much like chemistry, bio-chemistry sometimes. One must understand the elements and how they interact. One must use various tools to separate or modify the elements. Each chemical process results in something useful for the purpose it was created. Some combinations of chemicals are very volitile, others benign, but all must be given respect.
De-Identification Procedure
The procedure is simple. Ill include only the high-level, each step is more involved than I indicate here.:
- Identify what it is you want to do with data. This is your use-case. What are critical data attributes, and what are acceptable tolerances for each data attribute. You need to justify each element you want. You must also identify the acceptable level of risk, which includes assessment of the authorizations you have.
- Identify ALL of the data elements that you have. This is the data set that has not been de-identified. It might be a database, it might be a stream. You must identify all of the data, not just the data you are worried about. You then classify each attribute: Direct, Indirect, or simple data. Note that any unstructured data, otherwise known as free-text, must be considered Direct Identifier.
- Apply Mitigations, in theory. Given the use-case details you created in (1) and the data-element inventory you created in (2); apply the de-identification tools. (a) Redact - delete element, (b) Fuzz - modify within tolerance, (c) generalize - broader terms, or (d) replace - pseudonym. These are clearly not all the tools but the large categories of tools.
- Assess risk, in theory. How correlated are the data to a subject? Is this level of risk acceptable to the policy identified in (1)? Don't change your policy, that is the easy way out. Continue to apply mitigations. If further mitigations results in data that are not useful to your use-case, then you might need to change something else.
- Apply Mitigations to data-set and validate the results. As with any design-of-experiments one must be able to prove your theory. Is the resulting data just as de-identified as you expected? Is the resulting data useful for your use-case?
However well you have de-identified, recognize that there is residual risk that needs to be managed. This risk is often significant thus requiring good security practices. Just because you think your data are de-identified, does not mean you don't need to protect it. Attacks against de-identified data only get better, they never get worse.
De-Identification is Contextual
I have said exactly this (
De-Identification is highly contextual) before. the de-identification algorithm you come up with will not be useful to a different use-case, or a different data-set. It might be, but the assessment needs to be made. The context behind the needs of the use-case are critical. Take only the data, and the fidelity of the data that you need.
Gross De-identification
There are use-cases for doing a gross de-identification into a large data set, followed by secondary use-cases with their own further de-identification analysis. This is often done in population-health analysis, using gross de-identification to fill the population database. While re-assessing results of any sub-analysis of a specific population health epidemic. Clearly the large database needs to be protected quite strongly, I might say it needs to be protected just as well as a full fidelity database.
Summary
De-Identification is a technical tool. It is not a get-out-of-jail card. The resulting data set likely still requires some protection and safe handling.
See also: De-Identification
 on mHealth security basics, risk-assessment models, network communications security, and user identity and access management. This information is on the HL7 FHIR site, and will improve over the coming month. Front and center is the IHE-Internet User Authorization (IUA) profile, a profiling of oAuth 2.0. Much of the material I cover is also covered on my blog at the following:
on mHealth security basics, risk-assessment models, network communications security, and user identity and access management. This information is on the HL7 FHIR site, and will improve over the coming month. Front and center is the IHE-Internet User Authorization (IUA) profile, a profiling of oAuth 2.0. Much of the material I cover is also covered on my blog at the following: