Provenance and Audit seem to be recording the same thing, therefore why do they both exist and further why are they different?
Much of my response is focused on FHIR, but the concept is broader too.
Theory

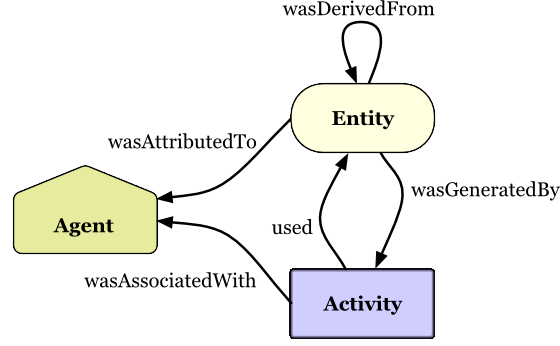
In HL7 we are trying to harmonize the historic healthcare use of Provenance and Audit, with a model of Provenance that is put forth by W3C. We must understand there is a theoretical Provenance concept that is primarily what W3C is focused on. Yes it has implementation models, I am not saying it isn't complete, however it doesn't have a HTTP REST model. So we need to build one. And we have.

Provenance is a record that describes entities and processes involved in producing, updating, delivering, or otherwise influencing resources. Provenance provides critical foundation for assessing authenticity, trustability, and traceability. Who authored and why, who updated and why, where were these changes, when were these changes, and what influenced these changes. When data is moved, Provenance tracks where the data came from. In W3C it also tracks who accessed, or where the data was sent.

Audit is broader including any Privacy or Security relevant event, not just actions upon data (Create, Read, Update, Delete). Audit is used to capture all actions upon data, but also actions upon other protected resources. The Audit log exists to provide evidence that a system is working properly, and thus is used to detect when it is not working properly. So it is used to detect failures in Confidentiality, Integrity, and Availability. So it is used to provide reports such as an Accounting of Disclosures. See
Guest Post: Use-Case - Security Audit Prompts Investigation
Reality
We must understand that in FHIR, that Provenance theory has been distributed differently. Much of this because of the momentum of healthcare, meaning we must recognize our own legacy. Second because healthcare is so very tied to Provenance as a concept, it is not new to healthcare, it is found in all our standards going back many decades. In historical systems they have a view that Provenance and Audit log are simply part of the database. So we are not new to this concept domain.
There is a 'view' in
FHIR, the W5 (Who, What, Where, When, Why) report shows, much of the purpose of Provenance (in medicine) is handled by elements in each of the clinical and financial resources. This doesn't mean an additional
Provenance record can't exist, but it means that in those cases to create a Provenance record is to duplicate the essential elements, which few will choose to do. BUT THEY CAN. The
FHIR Provenance resource is there for those cases where an additional record is desired to cover the cases where an explicit record of provenance is desired.
The
FHIR Provenance is only recording the provenance of a Create or Update; okay that isn't fully true as during a Transfer we record where it came from, etc. But
Provenance is not there to record READ operations. The most likely use of
FHIR Provenance is for import use-cases, to indicate where the data came from which might be different than the provenance information contained within the resource.
FHIR Provenance also covers things like putting a Signature across the targeted resources. It covers explaining how prior-evidence (entities) were used. It allows for explaining who (agents) was involved in the activity that produced the update. Mostly it fits well within the FHIR model, leveraging FHIR representations of the target, agent, entity, location, etc.

The
FHIR AuditEvent resource is there to cover more than W3C provenance covers when they say they cover audit. The
AuditEvent can record any event, not just provenance relevant events.
AuditEvent can cover any security or privacy relevant event, not just operations on data. The big one that we point out, just to prove the point, is that
AuditEvent can record logon events, both successful and failed. This is helpful in healthcare where, unfortunately, many healthcare systems still do user authentication rather than using an enterprise class authentication service (e.g. SAML, OAuth, etc).
AuditEvent is there to record Query operation, not something that is Provenance based. There are other events too. And like Provenance it fits well within the FHIR model, leveraging FHIR representations of agent, entity, location, organization, etc…
Breadth of the event is different.
Provenance record might be on a larger operation (activity), whereas there might be many Auditable 'events' that happened during that 'activity'. For example to create an Order for some procedure, the Clinician would have reviewed many parts of the record, would need to align with the Encounter, and might have needed to create a few ancillary resources that go along with the Order (like Specimen). There would be one Provenance record on the DiagnosticOrder (actually unusual as DiagnosticOrder contains all the Provenance they desire, but for argument sake), it would point at the evidence that Clinician determined important from the whole record she reviewed (difference in Provenance.entity from all the AuditEvents recorded).

The Audit log is designed to include many redundant recording actors making redundant records, so any action like a Create of a resource instance might result in many (usually at least 2) Audit log entries. This redundancy is part of the pattern used to see that a system is working properly. As such, the Audit log tends to need to be analyzed and pruned through various filtering, reporting, alerting, and offloading.
So, for every piece of Data there might be a Provenance record, or it might be contained within the Data. One Provenance record can point at many pieces of Data. The graph shown is just a visualization of the 'number of' entries of data vs entries of audit log vs entries of provenance records. It is not intended to be complete, but representative.
But for every access to data there will be an AuditEvent, including accesses to the AuditEvent record will produce another entry in the AuditEvent. And there are also AuditEvents for login, system-startup, system-shutdown, etc. Thus making AuditEvent the most popular Resource in FHIR.... by definition.,
Utility driven by Use
The biggest difference is in use-cases over time.
- is accessed by support staff such as Security Office, Privacy Office, and IT Office
- is analyzed quickly, within minutes/hours/days.
- it might get filtered and forwarded, reports might get made,
- some of it might get purged, other moved to offline storage.
- is accessed by clinicians, billing, quality, safety
- it might not ever be referenced, as it an unusual situation that doesn't have the data
- is part of the medical record, it lives as long as the data, and
- it goes with the data (should).
Exceptions to that general pattern do exist. But they are exceptional cases.
Provenance and Audit are both critical
I hope I have explained WHY we are not just adopting the W3C Provenance model. It is a model, we are looking toward it as a good model. But we are building something for Healthcare, and using FHIR. So there will be differences.
"All models are wrong, some are useful."
Updated: March 9th, 2016 -- fix the last graphic to be a bar-chart to better show this as a visualization of the number of entries, not to be confused with a Venn diagram concept of the other charts. Also swapped the first two diagrams so that a diagram of my work was first, the second is from the FHIR specification.