This is a very impressive and well written document. It does a good job of explaining the problem space, provides tools to use to determine the risks, provides tools to help with data minimization (de-identification), and very nice guidance on what a standard can do about privacy vs what must be handled later in a system or operational design.
- Section 2 describes the extent to which the guidance offered here is applicable within the IETF and within the larger Internet community.
- Section 3 explains the terminology used in this document.
- Section 4 reviews typical communications architectures to understand at which points there may be privacy threats.
- Section 5 discusses threats to privacy as they apply to Internet protocols.
- Section 6 outlines mitigations of those threats.
- Section 7 provides the guidelines for analyzing and documenting privacy considerations within IETF specifications.
- Section 8 examines the privacy characteristics of an IETF protocol to demonstrate the use of the guidance framework.
RFC-6973: Privacy Considerations for Internet Protocols
http://tools.ietf.org/html/rfc6973
[RFC3552] provides detailed guidance to protocol designers about both how to consider security as part of protocol design and how to inform readers of protocol specifications about security issues. This document intends to provide a similar set of guidelines for considering privacy in protocol design.
Privacy is a complicated concept with a rich history that spans many disciplines. With regard to data, often it is a concept applied to "personal data", commonly defined as information relating to an identified or identifiable individual. Many sets of privacy principles and privacy design frameworks have been developed in different forums over the years. These include the Fair Information Practices [FIPs], a baseline set of privacy protections pertaining to the collection and use of personal data (often based on the principles established in [OECD], for example), and the Privacy by Design concept, which provides high-level privacy guidance for systems design (see [PbD] for one example). The guidance provided in this document is inspired by this prior work, but it aims to be more concrete, pointing protocol designers to specific engineering choices that can impact the privacy of the individuals that make use of Internet protocols.
Different people have radically different conceptions of what privacy means, both in general and as it relates to them personally [Westin]. Furthermore, privacy as a legal concept is understood differently in different jurisdictions. The guidance provided in this document is generic and can be used to inform the design of any protocol to be used anywhere in the world, without reference to specific legal frameworks.
Whether any individual document warrants a specific privacy considerations section will depend on the document's content. Documents whose entire focus is privacy may not merit a separate section (for example, "Private Extensions to the Session Initiation Protocol (SIP) for Asserted Identity within Trusted Networks" [RFC3325]). For certain specifications, privacy considerations are a subset of security considerations and can be discussed explicitly in the security considerations section. Some documents will not require discussion of privacy considerations (for example, "Definition of the Opus Audio Codec" [RFC6716]). The guidance provided here can and should be used to assess the privacy considerations of protocol, architectural, and operational specifications and to decide whether those considerations are to be documented in a stand-alone section, within the security considerations section, or throughout the document. The guidance provided here is meant to help the thought process of privacy analysis; it does not provide specific directions for how to write a privacy considerations section.
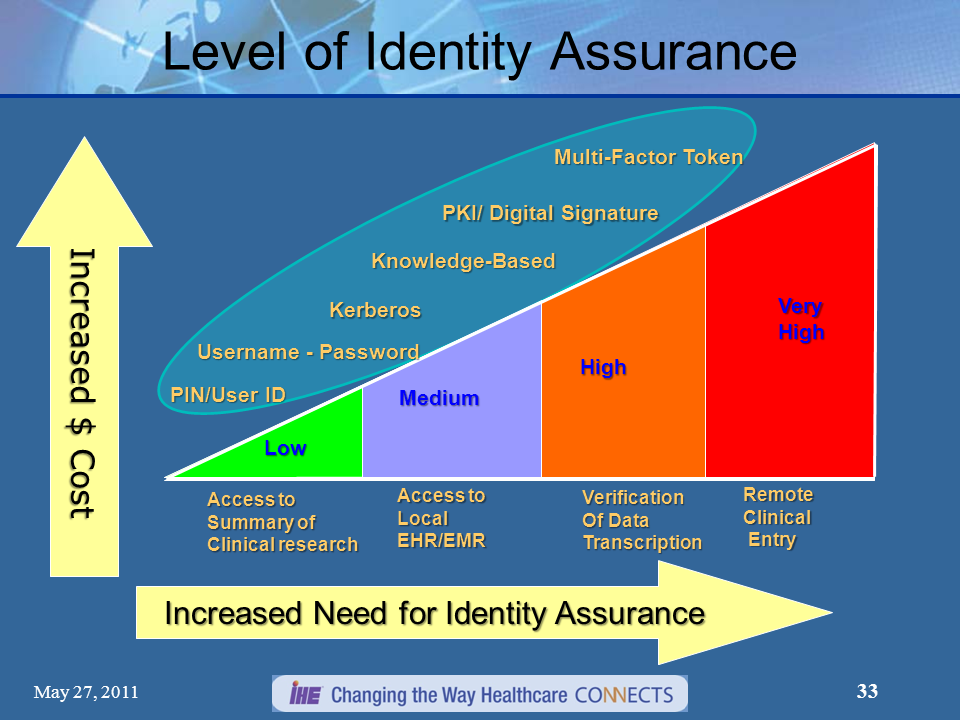
Patient Privacy controls (aka Consent, Authorization, Data Segmentation)
- Defining Privacy
- Safety vs Privacy
- Privacy Consent State of Mind
- Defining Privacy
- Universal Health ID -- Enable Privacy
- Texas HIE Consent Management System Design
- Simple and Effective HIE Consent
- IHE - Privacy and Security Profiles - Basic Patient Privacy Consents
- Data Segmentation - now I know where the term comes from