I have had some conversations lately around a De-Identification Service, specifically if it is possible for a general service that could be used like Actors within IHE. The problem that I have historically came up with is that there is no standard for defining de-identification policy, that set of rules that would drive the de-identification process in a way that (a) protects against re-identification, and (b) provides sufficient detail in the resulting dataset for a (c) given purpose.
There are standards on the concept of De-Identification, and I have written articles on the process. Key to any discussion on De-Identification is to recognize that it is a process, it is not an algorithm. De-Identification is not like Encryption, or Signatures for which one can have a defined algorithm. This because De-Identification is trying to balance opposing forces: The appropriate use of the data that needs specific fidelity to the data, against the inappropriate re-identification of the subjects of the data whose privacy must be protected.
IHE has defined a "De-Identification Handbook" that speaks to how to go about defining a De-Identification Policy, and addresses why this is something that is a process. This handbook helps you identify what parts of your data are direct identifiers and what are indirect identifiers. It identifies some common ways to change data during the de-identification process, such as redact, generalize, fuzz, replace, etc. The handbook also covers how to assess your dataset to see if your choice of policy is sufficient.
I have a general orchestration diagram in my Security and Privacy Tutorial - http://bit.ly/FHIR-SecPriv

This diagram is very abstract, presuming some kind of Query can be done by some Research Analytics App, that can be mediated by a De-Identification Service which if the request is authorized and appropriate can forward the request to a Resource Server. The Resource Server responds with the full fidelity data, the De-Identification Service mediates and de-identifies the data before returning the results to the Research Analytics App. This generalization presumes alot, including that the query can be mediated like this, and that the results can be de-identified in-real-time. Most De-Identification is done on a dataset, so that the resulting dataset can be analyzed to see that it has indeed met the goal of de-identification, often using an algorithm like K-Anonymity. The above could be done, but is far more of a systems design task, and not as simple as shown.
I think a more likely is that De-Identification Service orchestration is on a PUSH or FEED of data. That is not to say that it might not be a Query, but rather that it is a BULK of data. So, for example the FHIR Bulk Data Access might work. So, for this let's take a generic push set of Actors and Transaction.
In this diagram there is a data source and a data recipient and some standards-based transaction between them.
We then insert our De-Identification Service in between by Grouping a Data Recipient with our De-Identification Service and by also grouping a Data Source. Thus, the original two actors, are now end-to-end talking, but they are talking to each other with an intermediary.

We then recognize that the de-identification policy needs to be available to the De-Identification Service and must be administered by some Policy Admin
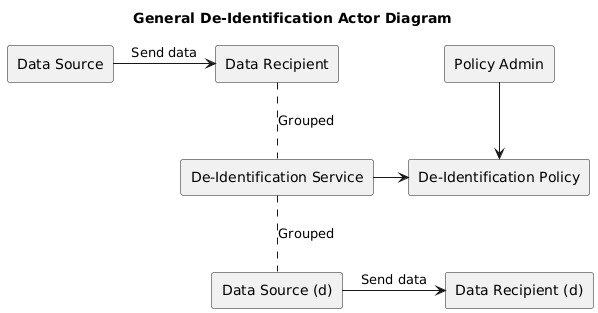
Unfortunately, I don't know of a Standard that exists for De-Identification Policy. So, these two actors can't really be defined. They need to be some functionality inside of the De-Identification Service.
So, this is the diagram I come up with. This is more than what I discussed above, as it starts with Document based sharing, and ends up with De-Identified FHIR Rest queries. Thus, the data is feed into the De-Identification Service (MHD), but that De-Identification Service groups a bunch (mXDE) of other IHE profiles and ultimately provides access to the De-Identified data using FHIR Rest (QEDm). This diagram does not abstract out the policy, it is part of the systems design.

I have used MHD and QEDm in this example. But given that I simply grouped within the De-Identification Server the peer Actor from those transactions; then the external view of the De-Identification Server is that it is using MHD and QEDm standards; essentially magic happens inside.
Similar can be done with other standards. This left as an exercise to my reader.
Hi John (HNY BTW) - have you looked at "https://cloud.google.com/healthcare-api/docs/how-tos/fhir-deidentify" - David
ReplyDelete