The healthcare IT exchange for Treatment has been improving from the dark ages to today. This article is where I muse about getting to that beautiful future based on #FHIR.
Break Everything
One possibly that some advocate is turn off what we have today, and everyone and everything switch to using http RESTful FHIR. Even to just leave what we have running, and build new only using http RESTful FHIR, would ignore current successes. There are some things we have learned getting to where we are that are unique to healthcare, for which http REST has not yet needed to solve. This "off/on" solution is not smart, agile, incremental, improvement.
Note I am not saying that using http RESTful FHIR is a bad idea, for green-fields it is a good choice, likely the best choice. Just that nationwide, there are considerations that are beyond http REST concept, that are indeed special in healthcare.
Another possibly is to just encourage anything and everything, hoping that someone will hit upon a successful solution. This is often referred to "let many flowers bloom", and is the model I hate the most. Yes this is the way evolution in nature works, but evolution in nature doesn't have the brains, lessons-learned, and planning power that humans have. We should not be using "let many flowers bloom" be used, it is not human.
Note, I am not saying that "let many flowers bloom" is always inappropriate. I do think that it is most of the time inappropriate.
Agile improvements
Agile approach builds on working systems, and pivots against non-working solutions. So let me explain an agile path.
We have a very mature and functioning nationwide healthcare exchange. We have two transports that can cross communicate, aka Karen's Cross. This pair of transports now has a third FHIR mode, so Karen's Cross is now three dimensional.
imagine a fancy graphic here that shows three sources each of the types: e-mail, SOAP, and REST talking to three consumers each of the types: e-mail, SOAP, and REST
For a good explanation of these transports, I refer you to the HIE-Whitepaper by IHE.
These transports are content format agnostic, so can carry old content, current content, or future content. Might be PDF, or CCD, or C-CDA, or v2-lab, or DICOM, or Tiff, or text, or comma-separated-values (CSV), or FHIR.
The query / retrieve model enables publishers to offer various formats of the same content. Meaning the same content could be offered in many formats. This might be published objects, or dynamically generated, or deferred creation entries. Thus a consuming system can select what is best for them.
Again, I will refer you to the HIE-Whitepaper by IHE.
CDA is here and it works
Much investment has gone into CDA. It has many positive attributes. People know how to make it do things therefore taking on new needs with small changes. CDA can take on new use-cases just as well as FHIR can. I am not going to try to argue that CDA is just as easy to understand as FHIR, but realistically when the content developers already know CDA, it is easier for them to improve CDA than it is to throw away their knowledge and learn FHIR, simply because there is a perception that FHIR is easier. It is not easier for them.
FHIR is not yet here, but it will be
FHIR is the new hotness, and it will most likely be the future, but it is new and it is still evolving. Likely 5 years yet before it is mature, it is a high-schools graduate able to flip burgers and dig ditches. Powerful and useful, but needing some more maturity. Note it took 5 years to get here, 5 more seems long but it will be here quick. Along the way FHIR will do good things.
First incremental step
So given that I do agree that the future will likely be far more of the FHIR based, I think the best way to get there is to make incremental steps toward that goal. Each step is going to be a bit unsatisfactory, but each step should move us toward that goal.
The reason incremental will work, is that the current systems already do function. So we are not starting from a broken system, we are starting from a sub-optimal system (some argue it is optimal, but I am willing to allow for saying current system is sub-optimal).
The Document Sharing Exchange allows for new content types to be easily supported. So where we might today be using C-CDA, the next incremental step might be to publish BOTH a C-CDA and a FHIR-Document (IPS). Include an association type linkage between them, so that a consuming system can know that they contain the same information in different formats. In this way a consuming system that has only ever understood C-CDA can pull the content it understands, and a different consuming system that prefers FHIR can pull the IPS content.
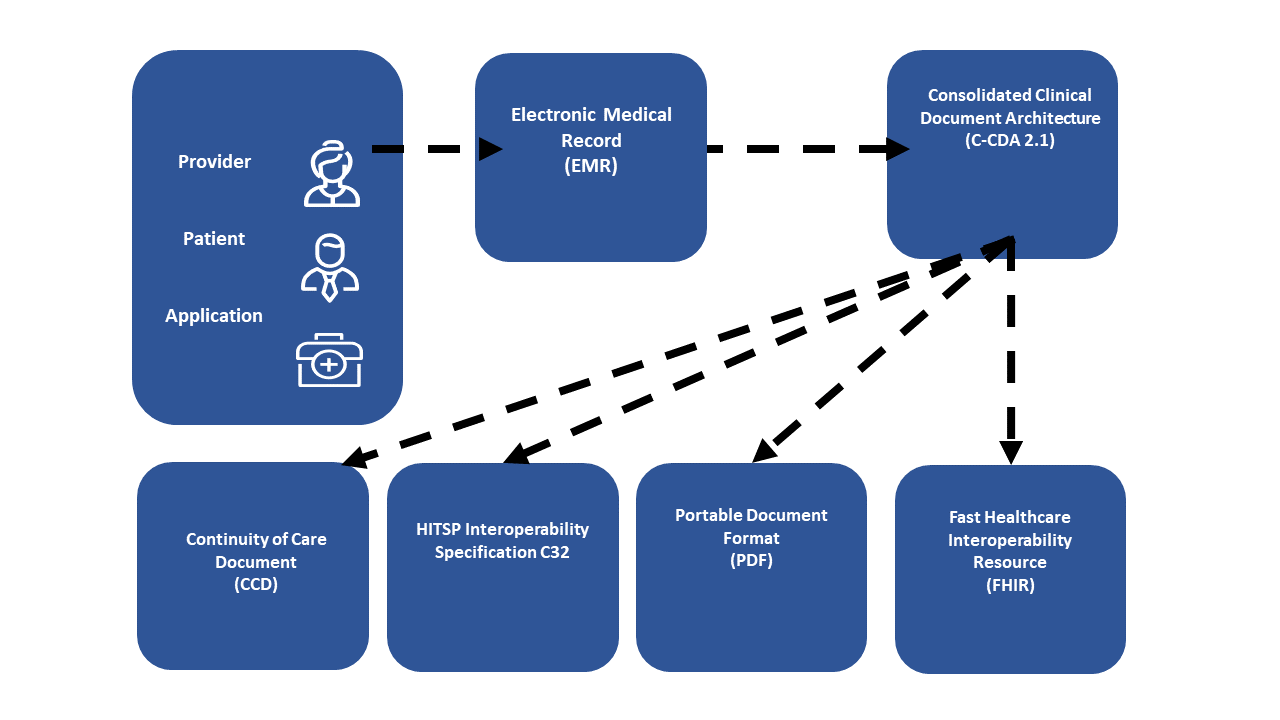
Again, I will point you at the HIE-Whitepaper - section 2.7 Document Relationships where this is discussed.
No comments:
Post a Comment